はじめに
今日は、Pythonのpandasライブラリを活用してcsvなどのDataFrameを読み込んで処理を行うということをやってみました。pyhonのメリットって、なにより高速なこと。VBAってなんか重たくないですか???ってことで本題に入ります。
今回やってみたこと
このサンプルcsv(sample_data)を活用して、読み込んで様々な演習をおこなうとのものです。
演習1:CSVファイルの読み込み
python コードファイルと対象のcsvファイルが同じ階層にあることを確認したらいか、以下コードを実行します。
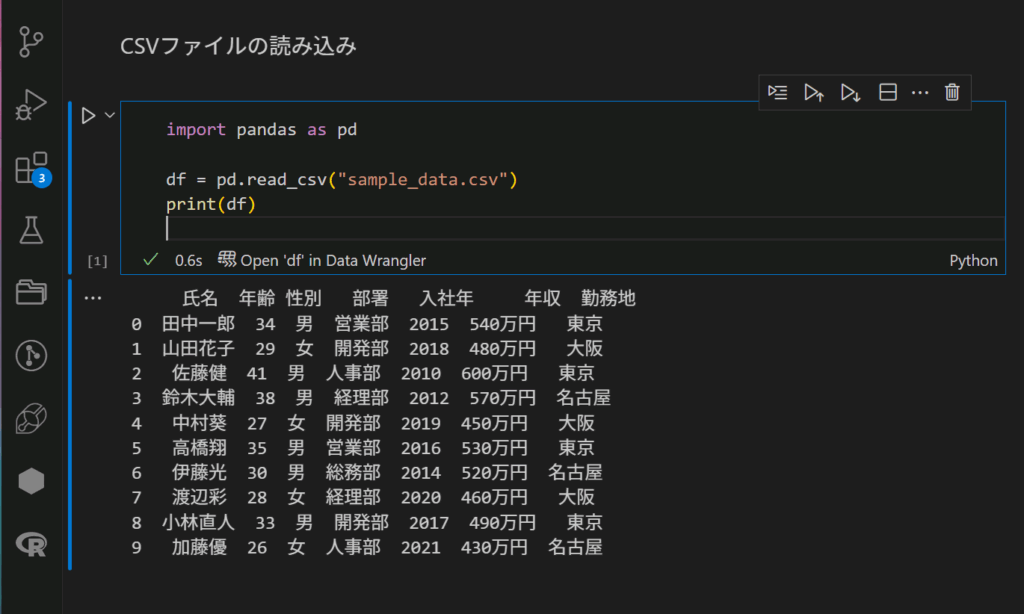
できました。たった0.6sでなんか嬉しいですね。やっていることは小さなことですが。。。
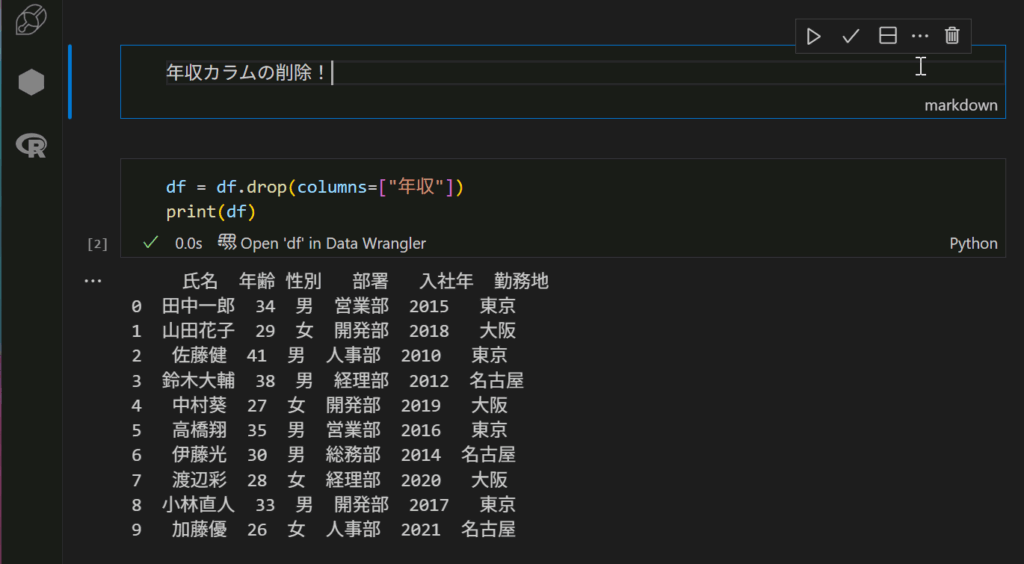
演習2:年収カラムの削除
演習3:「部署」以降のカラムをすべて削除
次は、部署以降のカラムを削除したい。この作業もよくありますよね。特定のカラムを検索して不要なら削除ってありますよね。それです。それ!それを実践してみました。
以下コードです。
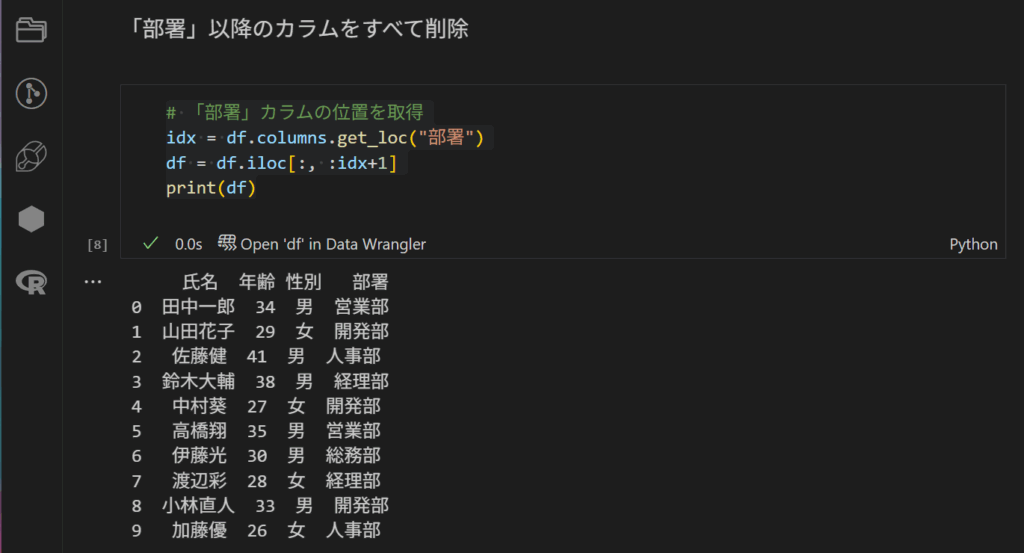
実行してみると、あらまぁ部署以降のカラムが削除されている!素晴らしい!これは使えそうですね。
ちなみに、部署も含めて削除した場合は以下コードで実行してください。
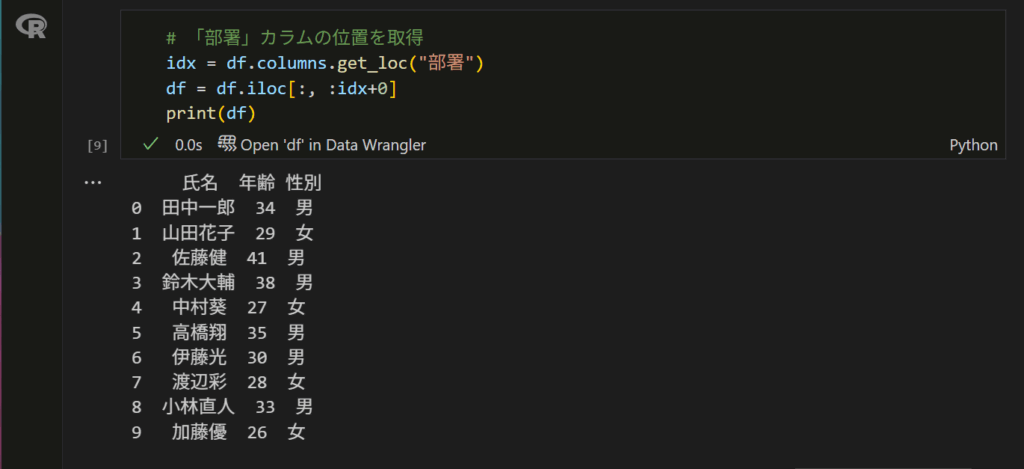
部署カラムも含めて削除されていますね!👏👏👏素晴らしい!
演習4:特定の文字列カラムだけ残す
つづいては、特定の文字列のカラムだけを残す。つまりそれ以外は削除を行うってものです。
以下コードです。
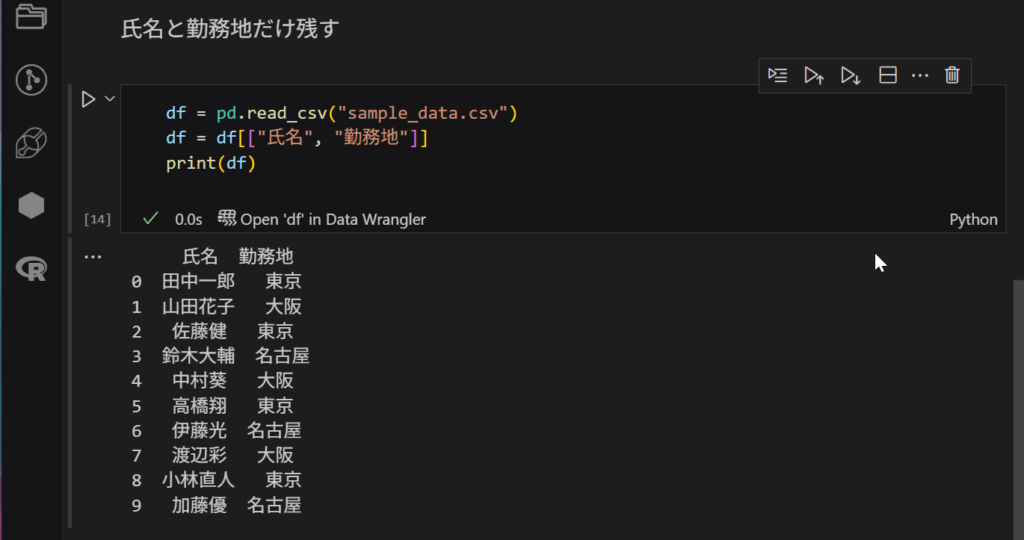
今回は、氏名と勤務地のカラムだけを残すにしています。実行できていますね👏
演習5:特定のカラムにソートをかける
今回は、特定のカラムに対して条件ソートをかけることで新たなDataFrameを実行に移すというものです。以下コードです。
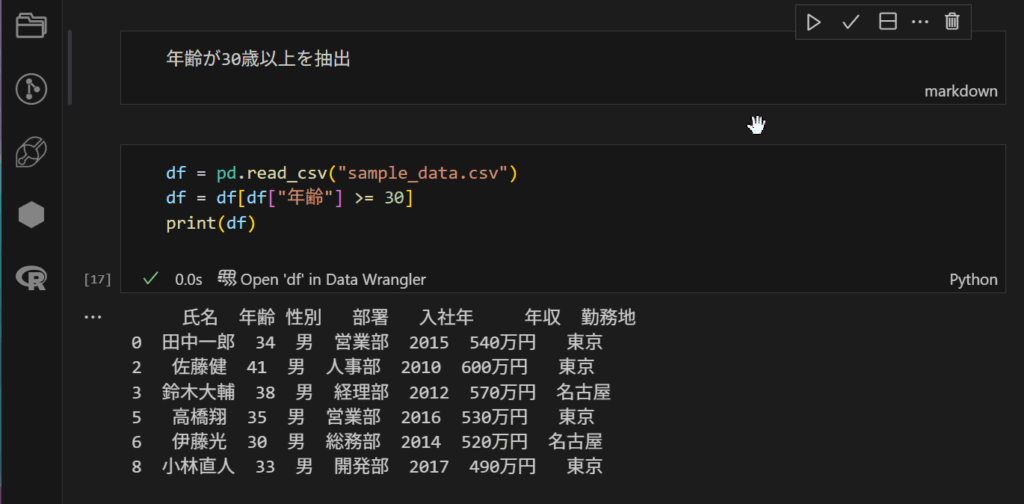
見事に、行が凝縮されていますね!👏素晴らしい。特定のカラムに対しての条件しばりもpythonから実装できるなんて便利ですねぇ~
ちょっと、応用編
次は、少しだけ応用編をやってみたいと思います。今までは指定のカラムの削除や指定のカラム以降の削除など、指定の変数が少なかったかと思われます。しかし、今回は指定の範囲のカラムを削除するということを実践してみたいと思います。
以下コードです。
import pandas as pd
# CSV読み込み
df = pd.read_csv(“sample_data.csv”)
# ステップ1:対象カラムを確認
start_col = “部署”
end_col = “年齢”
if start_col in df.columns and end_col in df.columns:
# ステップ2:「部署」から「年齢」までの列位置を取得
start_idx = df.columns.get_loc(start_col)
end_idx = df.columns.get_loc(end_col)
# 範囲削除:部署~年齢
df = df.drop(columns=df.columns[start_idx:end_idx+1])
# 表示(削除後に列を自動的に左寄せ)
print(df)
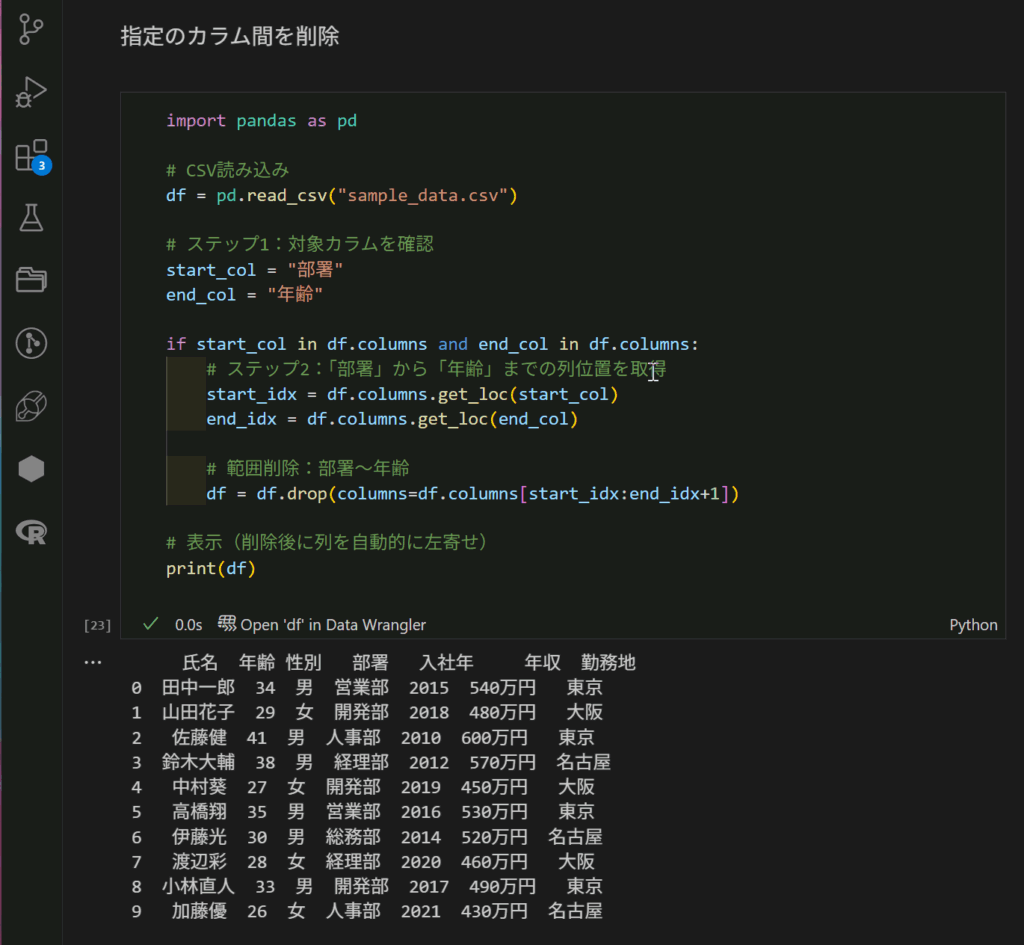
実行すると、、あれ??何も変わっていない。
以下コードで再度試してみた!
import pandas as pd
# CSV読み込み
df = pd.read_csv(“sample_data.csv”)
# ステップ1:対象カラムを確認
start_col = “年齢” # 開始のカラムは終了のカラムの左側
end_col = “部署” # 終了のカラムは開始カラムの右側?
if start_col in df.columns and end_col in df.columns:
# ステップ2:「部署」から「年齢」までの列位置を取得
start_idx = df.columns.get_loc(start_col)
end_idx = df.columns.get_loc(end_col)
# 範囲削除:部署~年齢
df = df.drop(columns=df.columns[start_idx:end_idx+1])
# 表示(削除後に列を自動的に左寄せ)
print(df)
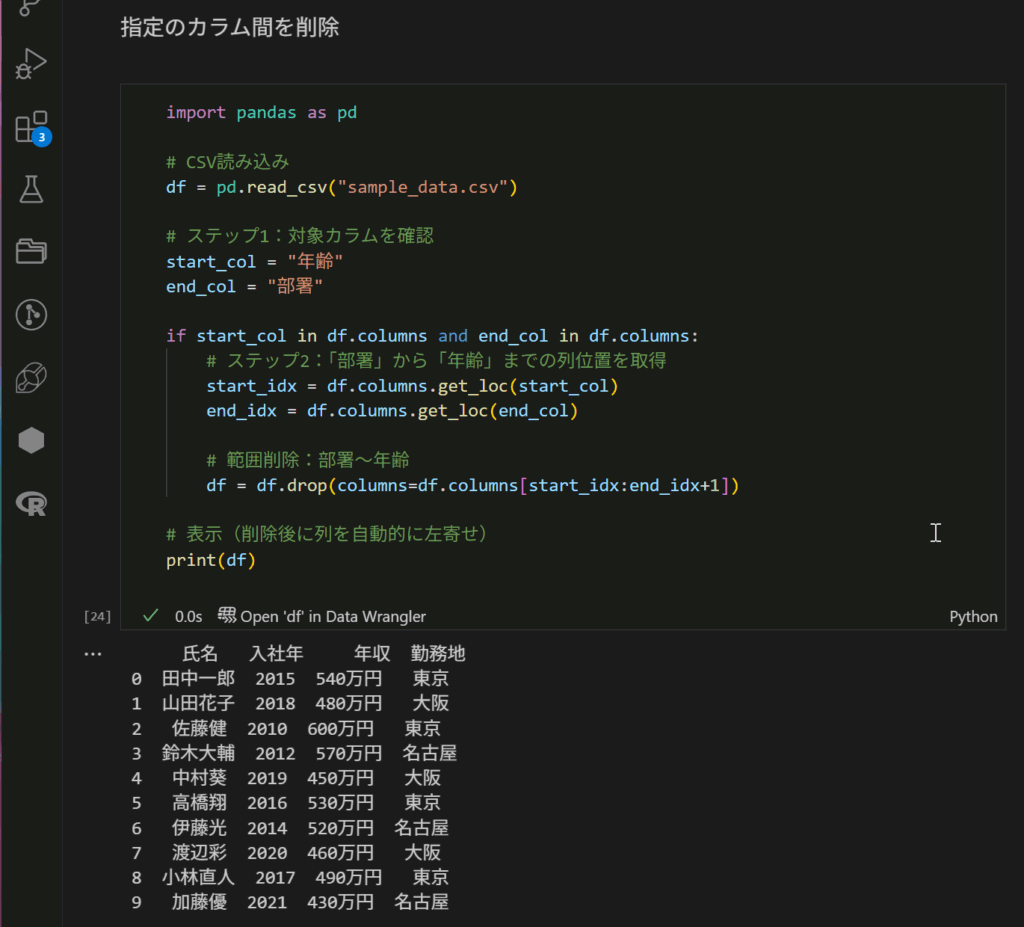
うん、できていますね。開始と終了の定義に問題があったようです。
ちなみに、開始と終了を同じカラムにすると一つのカラムの削除ができます。
さいごに
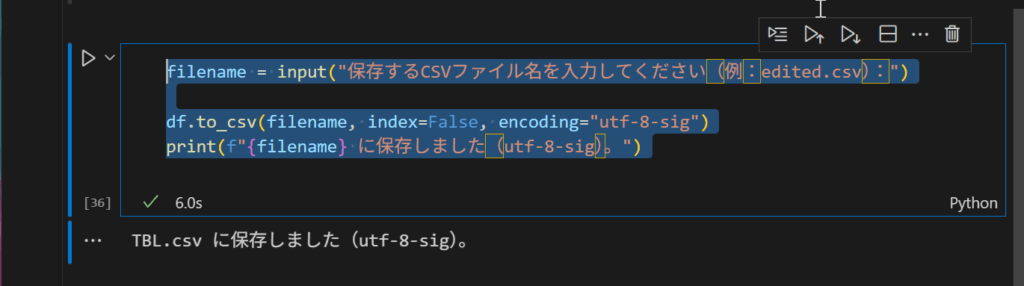
今回は、Excelやcsvの編集で行う作業のルーティン作業の効率化をpythonで行う実践記事でした。最後には、csvファイルへ保存して終了です。このときエンコードはとても重要です。しないと文字化けしますからね。。。
念のためコードです。