はじめに
最近、pythonを触るようになりました。そのため、押さえておきたい構文などについては把握できたらかなり便利だなと思ってまとめてみました。今回紹介するのは、pandas構文とfor構文、どちらも知っておくと結構便利な構文なんで紹介しておきます。
では、本題へいきましょう!
最強 pandas構文!
まずは、pandas構文の作業で使える作業について紹介をしていきます。今回は⇒CBBTCUSD のビットコインのヒストリカルデータのcsv ファイルを参考に処理を実行してみたいと思います。
ちなみに、このデータはAPIを使用して、FREDからデータを取得したものです。取得の仕方については以下記事を読んで見てください。(クリックしてね🖱)

データの読み込み
読み込みをしたいファイルと、実行したいファイルが以下写真のように同じ階層に保存されている。
そのとき、以下のようにコードを実行することで
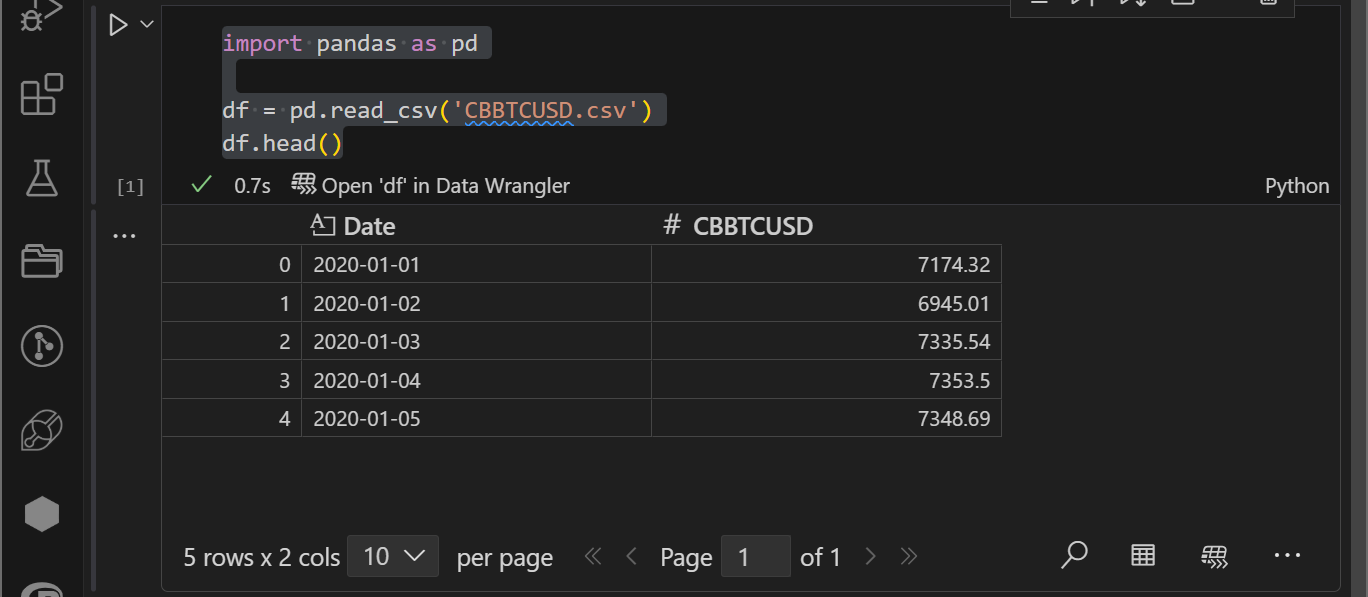
データ読み込みはpandas でDateFrameの編集を行うにあたり基礎!導入に該当する部分となります。
データの選択
指定したカラムを抽出する
価格列のみを抽出する。先ほど、読み込んだデータでカラムを指定して抽出したい場合は以下画像のような構文で実行することで対応可能です。
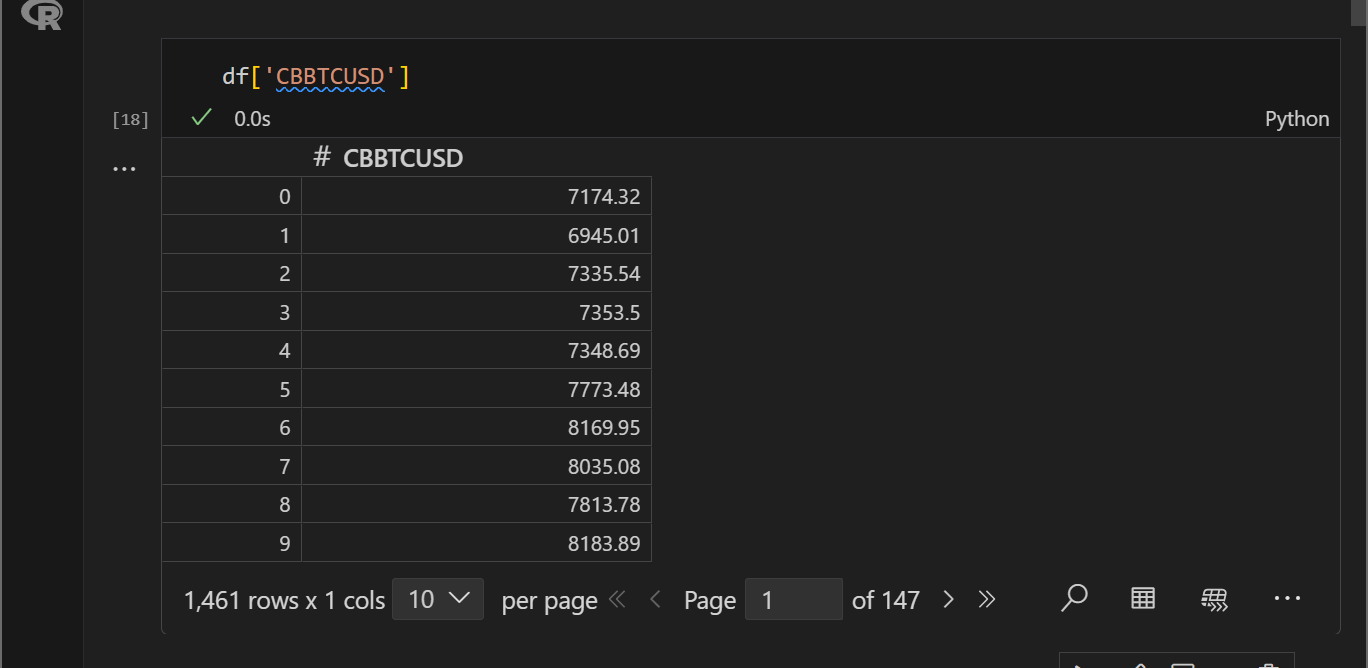
ちなみに、同様のことは以下のようにしてもできます。わたしはこちらの方がよく使います。
指定の行の情報を取得する
先頭行のデータのを取得するには以下の通りで可能です。最初の行だけを抽出することはあまり使用しないかもしれないです。
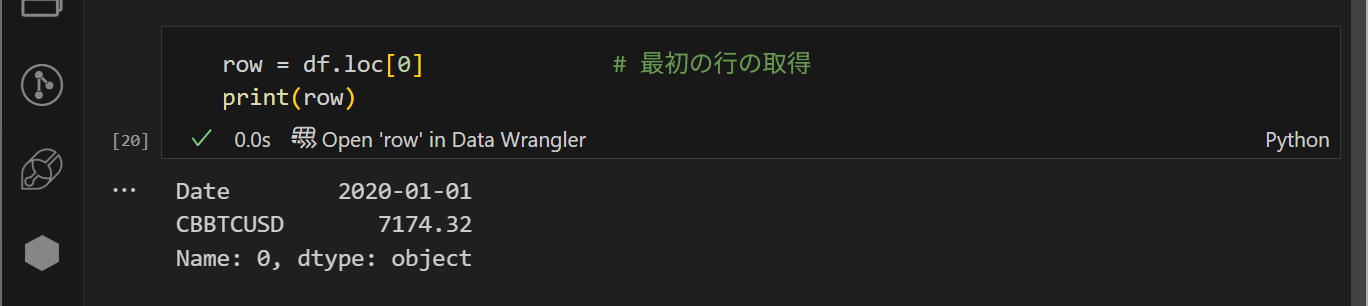
ここでポイントなのは.loc[]によって、指定の行データを抽出することができるということです。
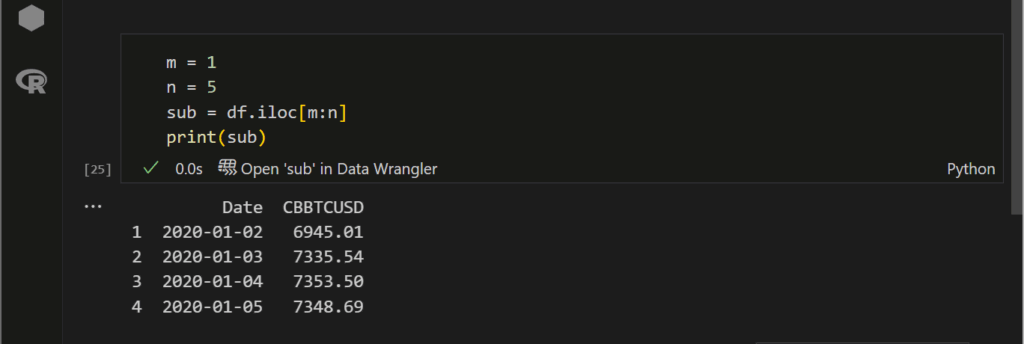
👆のような感じですね。文字でも置き換えることができますね。条件で指定することができて応用がききそうですよね。まぁ、int型にしないとエラーがでるとか細かい問題はありますけどね。
条件でカラムのデータをソートする
特定の指定の条件にソートする方法について紹介します。今回は、指定の価格カラムがある数値以上の場合にソートかかるようなコードとしています。
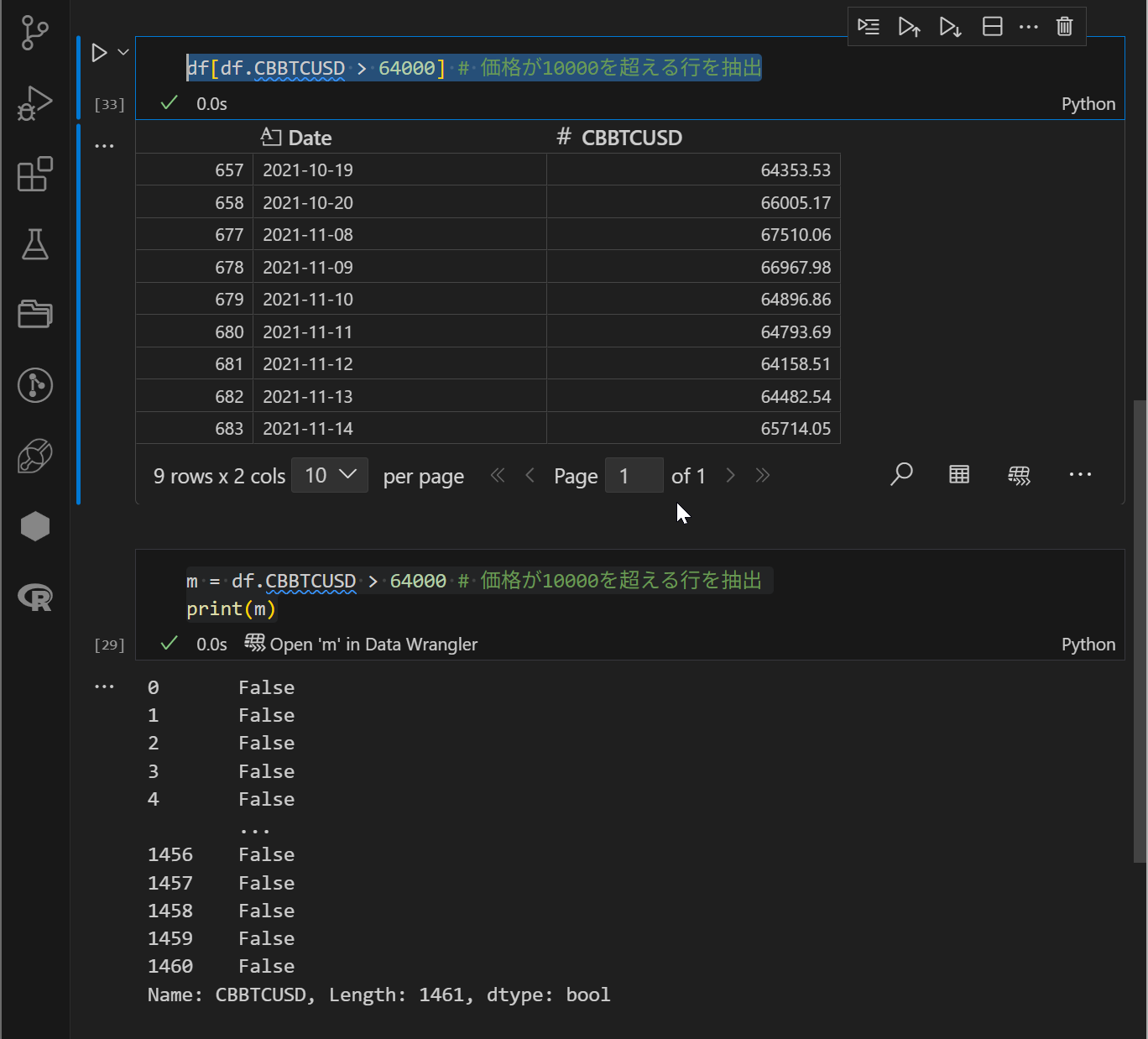
ここでの注意点は、df[df[‘カラム名称’]]とコーディングする必要があります。df[df.カラム名称]というコーディングではエラーがでます。なお、m =のように定義を行ってプリントを行うこともうまくいかないです。
知ってると便利なfor構文!
for構文とは、基本構文は以下のような構成となっています。
for 変数 in イテラブル=’一つずつ順番に取り出せるオブジェクトのこと’:
処理
イテラブルってなに?上記のコードにも記載していますが、一つずつ順番に取り出せるオブジェクトのことです。ん??どういうことって思った方もいるかと思いますが具体的には、以下の通りです。
・list : [‘a’,’b’,’c’] 順番に要素を取り出せる
・tuple : (‘x’,’y’,’z’) リストと似ている。
・str : “hello” 一文字ずつと取り出すことができます。
・dict : {‘a’:1,’b’:2}
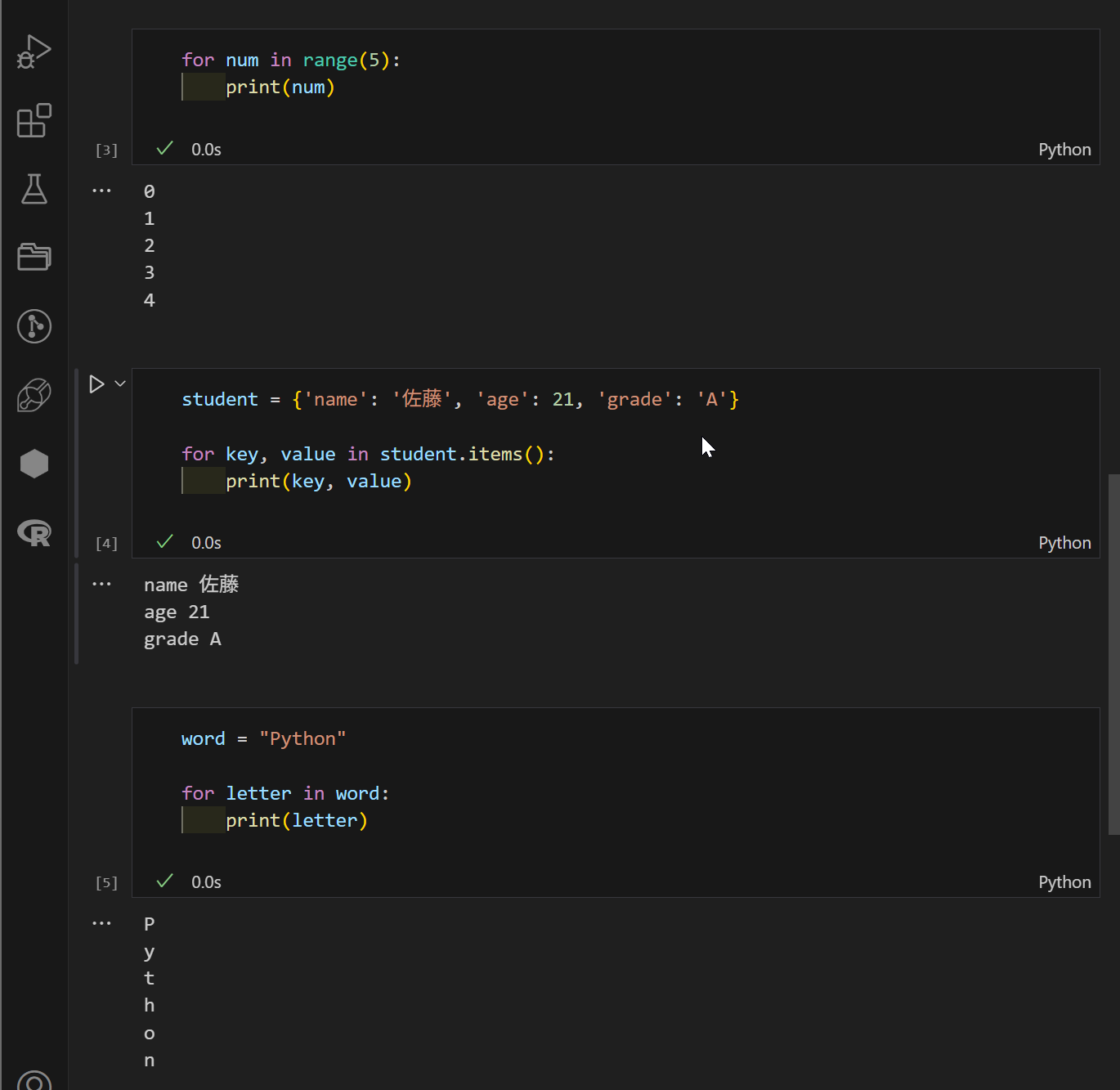
・range() : range(5) 0~4の数字を順に取り出すことができます。
・DataFrame.itrrows() : for_, row in df.iterrows() 行オブジェクトの繰り返し
以下、実行結果です。リスト型の場合は、このような感じになります。
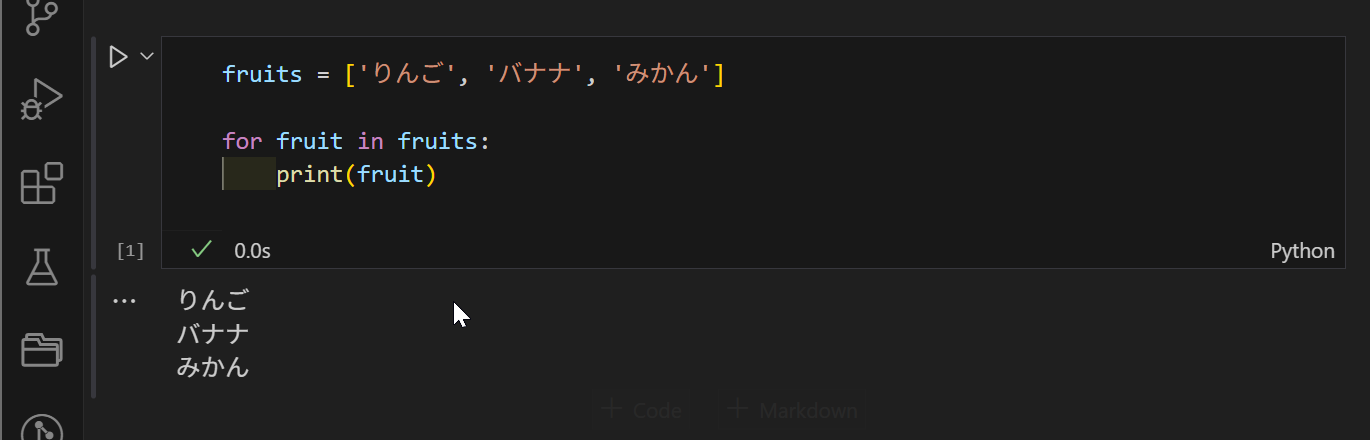
また、range():型のタイプは結構便利です。numの値に指定の数字を順に代入していくタイプです。ほかのタイプも記載していますので、参考にしてみてください。