
はじめに
今回は、PythonでAPIを使用して株価の取得をしてみました。簡単なグラフの生成までやってみましたので、一連の流れをまとめてみます。
ライブラリの準備を行う
前提条件の整理
yfinance側 の前提条件の設定
赤字のyf.downloadについては、ライブラリyfinanceによる関数です。
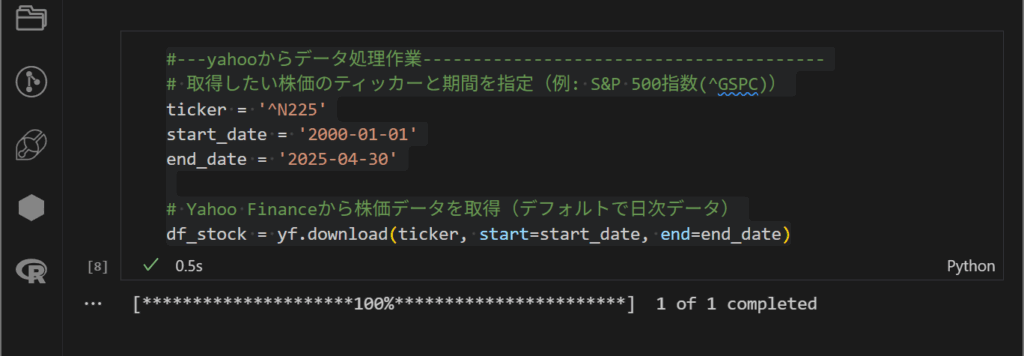
FRED の前提条件
# ★★重要ループ処理の実行—————————————————
肝となる for 構文
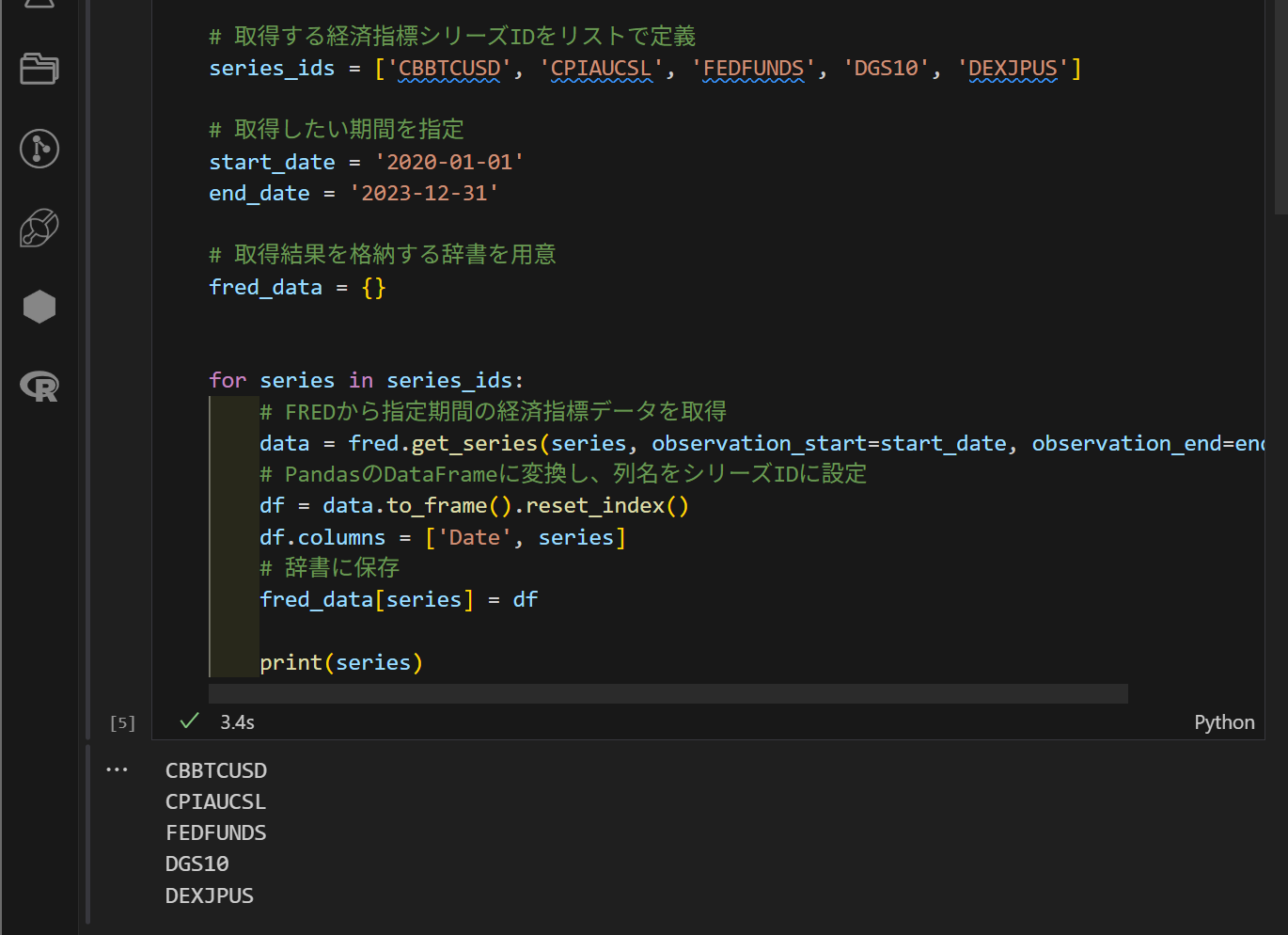
今回は、FREDから複数の経済指標データを取得するため、Python の for ループ構文を用いた処理を行います。get 関数では、ティッカーコード、取得開始日、取得終了日を指定してデータを取得する必要があります。
以下は、そのループ処理の概要です。
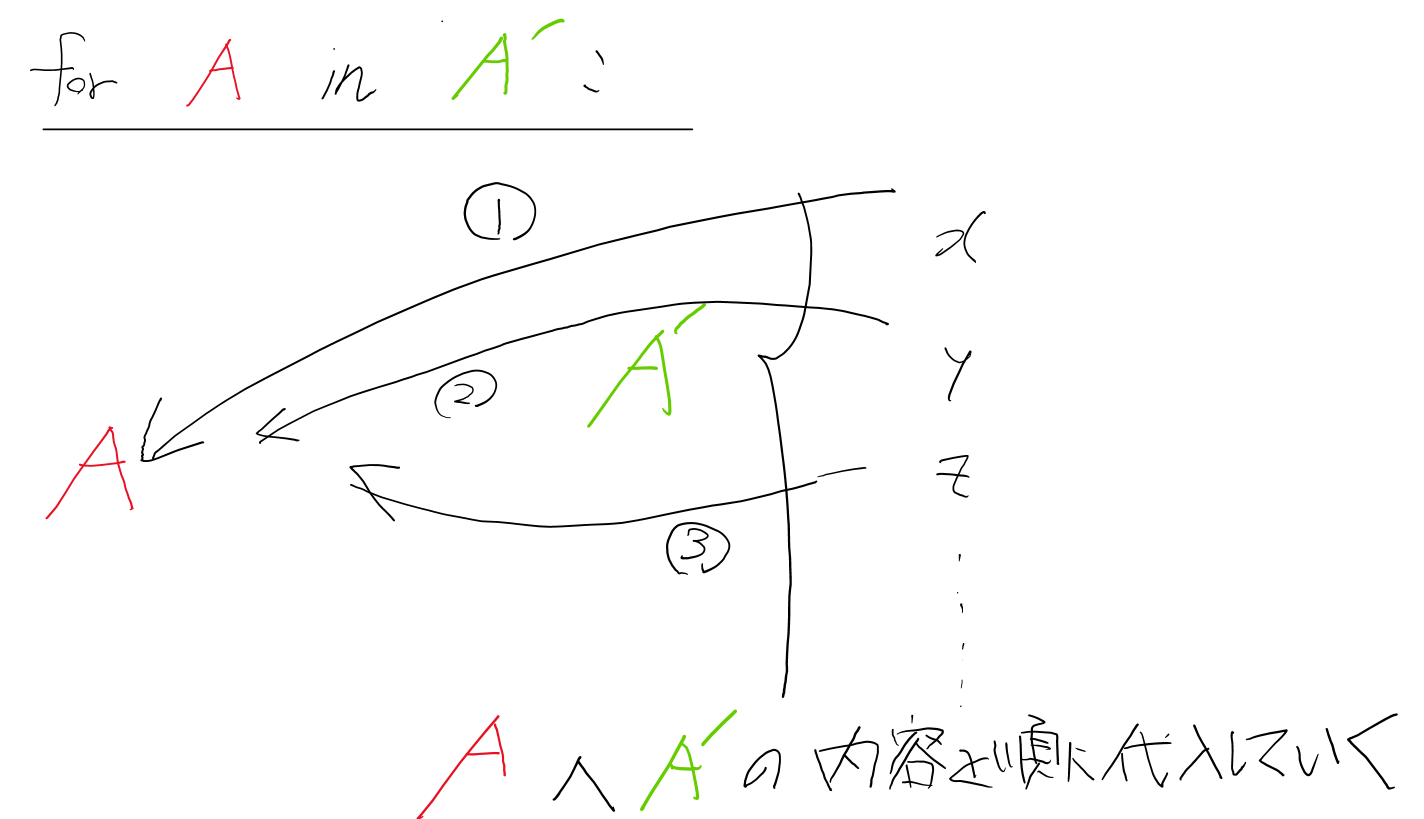
今回は、ティッカーコード(銘柄コード)を順番に処理するため、リスト型を使用しています。これにより、各ティッカーコードをループ処理で順に取り出して扱うことができます。
for文直下にget関数を使用することでfor文と組み合わせたget関数を使用することができます。ちなみに、

その他の処理
data.to_frame()というコードもfor文直下に存在するかと思います。こちらは、index型をDataFrame へ変換しているものになります。

複数の銘柄のデータを一括で取り扱うために行われる処理です。
CSVファイルへの保存
取得したデータをcsvデータとして保存します。そのためには、まずデータのカラムを整える作業が必要です。2STEPに分けて解説していきます。
データの前処理_yfinance
reset_index 関数
★:テーブル名.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”)
⇒inplaceの上書きするか否かって、ところが頻出です。
Date indexを列へ変換することで、読み込みやすいデータとすることができます。
df_stock.reset_index(inplace=True)
👇は、実行前と実行後の様子です。👈側は、実行前ですが、Dateがindexに含まれているため、列として表示したいです。そこで、reset_index関数を使用します。
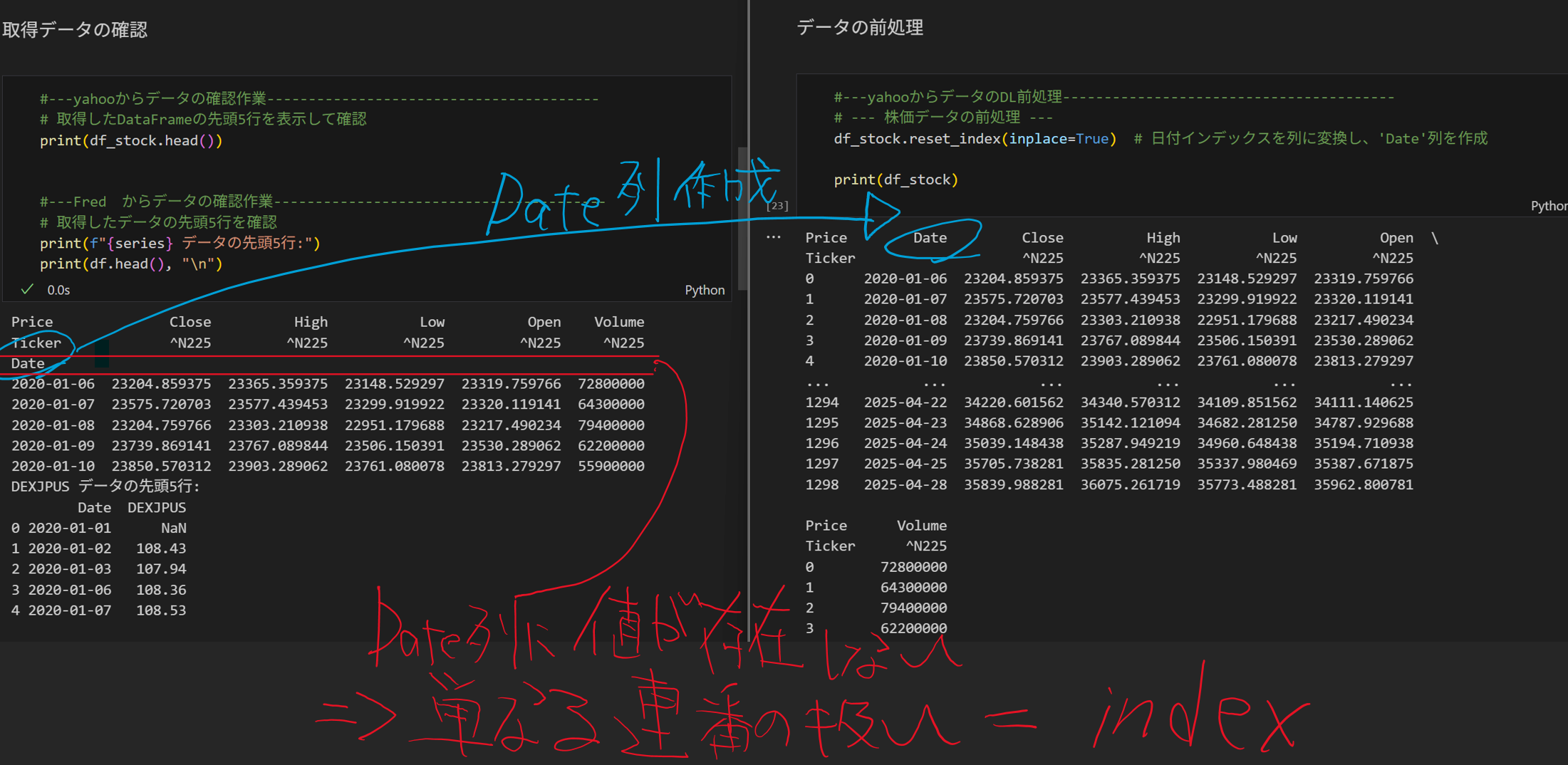
reset_index関数を実行すると、indexはカラム(列)として変換されます。問題は、indexの定義ですよね。indexとは、行で行の横(つまり、カラム列データを持たないもののことです。)
rename 関数
★:テーブル名.rename(columns={‘元の列名’: ‘変更後の列名’}, inplace=True)
df_stock.rename(columns={‘Adj Close‘: ‘Adj_Close‘}, inplace=True)
このコードの意味としては、列名に空白が存在する場合、空白を_に置き換えるというものです。今回は、もともと列目に空白が存在しなかったので不要のコードとなっています。
Pandas × datetime
★:pd.to_datetime(’変換したい値の引数’, format=None, errors=’raise’, utc=False)
⇒pd.to_datetime().変換希望の型 とすることで、指定の引数を希望の型へ変更できます。
df_stock[‘Date’] = pd.to_datetime(df_stock[‘Date’]).dt.date
今回は、df_stock[‘Date’](df_stock という DataFrame の'Date' という 列(カラム)のことです。この通常、日付型はdatetime64[ns]で表記されるため、年月日までの表記となる.dt.dateへ変換します。なお、今回はコード実施前後において変化はないです。元データの日付データ(年月日)のためです。
データの前処理_FRED
.copy 関数
★:fred_data[シリーズID].関数()
⇒基本の型。fred_data(辞書の型)であり、シリーズ名の値を持つ。その中から、シリーズ名を選択し、関数を実行します。
df_unrate = fred_data[‘CBBTCUSD’].copy()
ビットコインのデータフレームをコピーします。
その他にも例を挙げると
fred_data[‘CPIAUCSL’].head(3) # 先頭3行を表示
fred_data[‘DEXJPUS’].describe()
数値列の要約統計量(平均・標準偏差・最小値・四分位数など)を出力します。
fred_data[‘DGS10’].tail() # デフォルトは5行
Pandas × datetime
yfinaceでも行いましたが、FREDのデータ処理もこちらは行います。
df_unrate[‘Date’]= pd.to_datetime(df_unrate[‘Date’]).dt.date
定義 = pd.to_datetime(対象の列).対象の型
yfinaceの時と同様に今回のデータ処理では、元データが日付の型(年月日)であるため、実行前後での変化はありません。
(Pandas × datetime)×for構文
上記の処理を複数の列に対して、実行したいです。その場合のコードについてです。
for series, df in fred_data.items():
df[‘Date’] = pd.to_datetime(df[‘Date’]).dt.date
今回fred_dataは辞書型であるため、fred_data.items()とすることでシリーズ名とDataFramemeを同時に扱うことができます。
正直イメージがつかない方が多いかもしれないですが、例で説明すると以下の通りです。
my_dict = {
‘A’: 1,
‘B’: 2
}
上記のように、A、Bのキーとその値を持つデータフレームとなっています。これらを辞書型といいます。
for key, value in my_dict.items():
print(f”key: {key}, value: {value}“)
上記のコードを実行すると、keyはA、B。valueは1、2であるため以下のような結果となる。
key: A, value: 1
key: B, value: 2
今回の場合で再度考えます。
for series, df in fred_data.items():
df[‘Date’] = pd.to_datetime(df[‘Date’]).dt.date
fred_dataという辞書のキー(経済指標のシリーズID)をseriesに、値(=それぞれのDataFrame)をdfに代入する。ループ内では、各dfのDate列を日付型に変換して.dateオブジェクトにします。
CSVファイルで保存
保存先フォルダの決定と作成
output_dir = ‘output_csv‘
os.makedirs(output_dir, exist_ok=True)
上記コードによって、自分でDLしたデータを格納するフォルダを生成する手間がなくなります。
output_csv
また、仮に
output_csv
その対応は、os.makedirs関数で行います。
os.makedirs(’変数名’, exist_ok=True)
変数名(フォルダ名)を作成します。また、, exist_ok=Trueを付加することですでにフォルダが存在してもエラーが発生しないようになります。
保存先フォルダへcsvファイルの保存
df_stock.to_csv(os.path.join(output_dir, ‘N225.csv’), index
=False, encoding=’utf-8-sig’)
df_stock は、Yahooファイナンスから取得した「日経平均株価のデータ」が入っている表(DataFrame)です。
.to_csv関数を使用することで、このデータをCSVファイルとして保存することができます。
csvとして保存するのは、いいですが保存先も指定できるとなおよいですよね。そこで使用するのが、os.path.join(...)関数です。この関数を使用することで、指定したデータを指定の保存先へ指定のファイル名で保存することができます。
データ(株価).to_csv(os.path.join(保存先, '保存するファイル名')
今回の場合は
df_stock.to_csv(os.path.join(output_dir, 'N225.csv')
df_stockデータをcsvデータとして、output_dirへ'N225.csv'のファイル名で保存をします。
また、
,index = False,encoding='utf-8-sig')
index = Falseとすることで、左端のインデックス番号はcsvとして吐き出さないようにします。
ループ処理で複数実行
for series, df in fred_data.items():
filename = f”{series}.csv”
filepath = os.path.join(output_dir, filename)
df.to_csv(filepath, index=False, encoding=‘utf-8-sig’)
上記の通り、fred_dateをkeyとvalueに分けて、seriesへ代入します。
fred_dataという辞書に複数の経済指標データが存在しています。それらのデータのkey,値を抽出し、それぞれseriesとdfへ代入し繰り返し処理を実行していきます。
また、最終的には以下のようにcsvファイルとして、指定のfilepathへ保存を行います。
df.to_csv(filepath, index=False, encoding='utf-8-sig')
おさらいで基本形は、以下の通りです。
データ(株価).to_csv(os.path.join(保存先, '保存するファイル名'),index = False,encoding='utf-8-sig')
今回の例では、(os.path.join(保存先, '保存するファイル名')の部分をfilepathと置き換えています。
そのため、事前に以下のようにfilepathを定義しています。
filepath = os.path.join(output_dir, filename)
そのため、filenameの定義も必要となりますよね。なので、filename はこのように定義するのです。
filename = f"{series}.csv"
ちなみに、上記のようにf”文字列 or {変数}”によって、文字列の中身や変数の式を埋め込めることができます。
まとめ
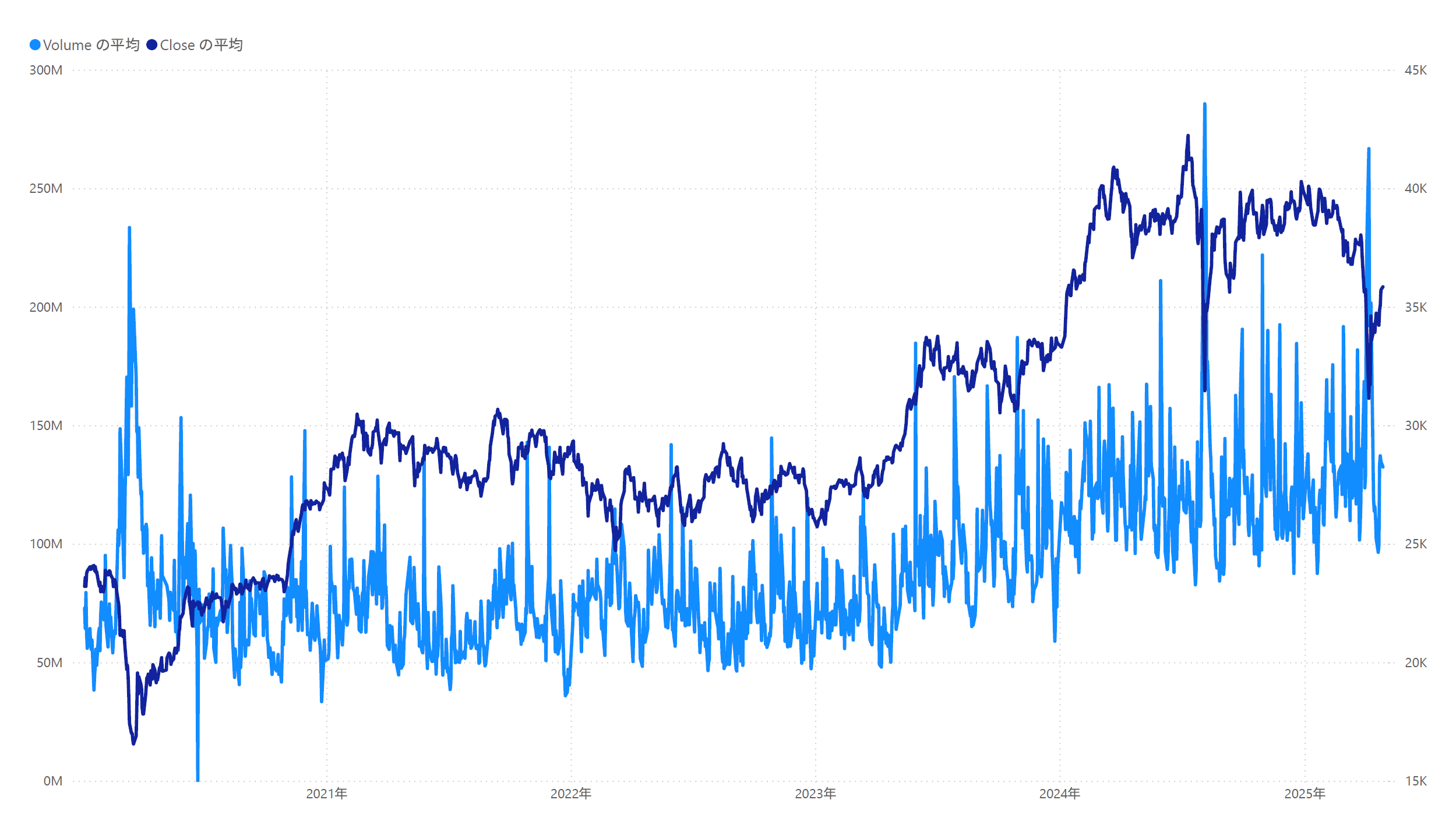
取得したデータで、添付のとおり出来高と価格推移のグラフを作成してみました。今回はPower BIを使用しています。Power BIの使い方やここからの分析については別記事で解説していきます。
今回は、FREDとyfinanceからデータを取得することをしました。基本構文を理解することが大事なので各パートの基本構文を理解するようにしてください。



