
はじめに
今回は、Pyhonを使用してwebサイトにあるHTMLデータを取得するということをやってみました。気象庁のサイトにて、実践しましたのでその流れを紹介いたします。
観測地点とデータ年を取得
前提条件の整理
今回の作業では、以下コードのようなライブラリを使用します。
webページへアクセスするために必要な’requests、webページ内にあるHTMLコードを解析すするのに必要な’BeautifulSoupなどのライブラリは特に重要です。
#気象庁のURLから確認を行う
prec_no = 42 # 地域番号(都道府県単位)
block_no = 1019 # 地域内の観測地点(ブロック)番号
import requests # Webページのデータ取得
import io # バイトデータの入出力用
from bs4 import BeautifulSoup # HTML解析用
import pandas as pd # データ整形・加工・Excel出力用
観測地点×年データの取得
前提条件で整理した、地点コードやライブりに基づき、観測地点と年データの取得を行っていきます。
#解析対象のURLを作成
url = “https://www.data.jma.go.jp/obd/stats/etrn/index.php?prec_no=” + str(prec_no) + “&block_no=” + str(block_no)
#解析対象のURLの内容を取得する
page = requests.get(url).content.decode(‘utf-8’)
#HTMLの整形を行います。
soup = BeautifulSoup(page, ‘html.parser’)
tables = soup.find_all(“table”)
上記のコードによって、対象のURLからおおまかなデータを取得しています。
ちなみに、取得した指定の地点tables情報は、下の通りごちゃごちゃしています。
ここからどのように料理をしていくか💦
観測地点名の取得
おおまかなデータを収集が完了したので、続いてHTML構造をたどり、観測所の名前の取得を行います。
しかし、先ほど確認したtablesのデータではどこのtablesにどこのデータが格納されているか分かりづらいので整理を行います。
for i, table in enumerate(tables):
for i, table in enumerate(tables) を使用することで、i へtableのインデックス(0,1,2・・・)と実行します。実行結果は、以下の通りです。tables[3]に地点名らしき要素を確認できました。
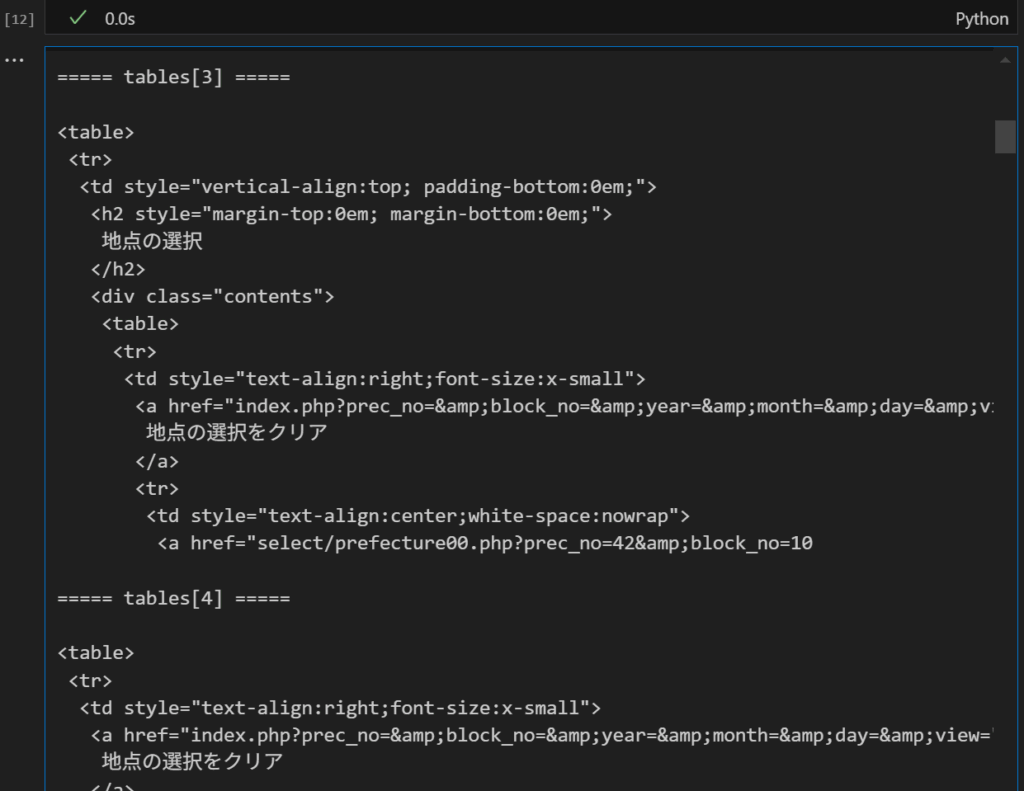
上記実行結果から、table[3]にあることはわかりましたが、みづらいですよね。もうすこしいじってみます。
for td in tables[3].find_all(“td”):
text = td.get_text(strip=True)
print(text)
.find_all(“td”):tables[3]内のすべてのセル(<td>タグ)をリストとして取得。
text = td.get_text(strip=True):セル内のテキストを抽出し、htmlタグと空白の削除を行う。

tabeles[3]のテキストは、上記の実行結果からもわかるようにぐちゃぐちゃしていますね。
地名を抽出したいので、県で検索でもしてみます。
for td in tables[3].find_all(“td”):
text = td.get_text(strip=True)
if “県” in text and len(text) < 20: # 「○○県 △△」の形式
print(“地点名候補:”, text)
if “県” in text and len(text) < 20:
>“県” in text 都道府県名が含まれているかを判定する。
>len(text) < 20 異常に長い文字列は除外を行う。
上記、sample codeを実行すると。。。

その他のやりかた
このコードについては、htmlの内部構造を理解していることが前提となるので、気象庁webサイトをよく利用する人向けですね。
stationName = tables[3] #左から4番麺の<table>タグを選ぶ(地点のある表)
.find_all(“table”)[0] #その中の最初の<table>内側の表を取得
.find_all(“td”)[3] #その中の4番目の<td>(地点名)を取得
.getText().strip() #中のテキスト(例:群馬県 みなかみ)を抽出&空白を除去する。
#動作の確認を行います。
print(stationName)

対応可能な年一覧の取得
つづいて、選んだエリアにおいて何年~何年のデータの取得できるかを確認します。コードを確認すると、find.all関数が重要な役割を担っていそうですね。
years = []
#年のリンクを取得します。
year_links = tables[3].find_all(“table”)[1].find_all(“table”)[0].find_all(“a”)
year_links = tables[3].find_all(“table”)[1].find_all(“table”)[0].find_all(“a”):
find.all():指定の条件で検索を行う関数。
今回の場合は、tables[3]の中に格納されているtableを抽出する。そして、抽出を行ったtableの中からさらに抽出を行う関数というもの。
.find_all(“table”)(“a”):年を示すリンクがすべて入っているものを限定に抽出をしている。
例)<a>2021年</a>
以下、実行結果です。year_links はごちゃごちゃとしていますよね。。。

👆の長いリスト(<a>~~~<a>,<a>~~~<a>・・・)から各年(数値)を取り出したい。。。そのために、以下コードで処理を進めます。
for yearString in year_links:
= 長いリストから<a>~~~<a>タグを一つずつ取り出します。
year = yearString.getText().strip()
= <a>~2023年~<a>から2023年のように文字列のみを取り出します。空白も除去します。
years.append(int(year[0:4]))
= 抽出した文字列の最初の4文字をだけ抽出し、文字列を数値へ変換のうえ、yearsへ格納します。
ーーー実行結果を入れる




