
はじめに
今回は、ちょっとデータ処理をマクロではなくpythonで処理を行ってみました。その流れについて紹介をします。
今回行う作業
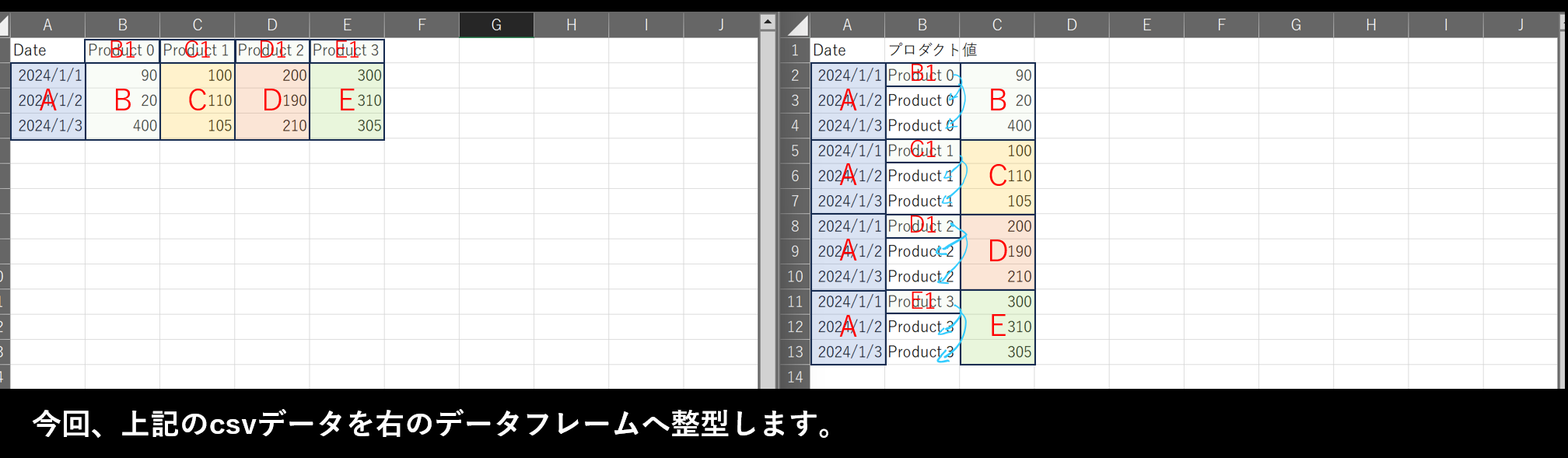
今回は、左側のcsvデータフレームを右側のように整型する作業を実行します。では、具体的にどのように作業を進めていけばよいのかを解説していきます。
対象ファイルの選択・読み込む
import tkinter as tk
from tkinter import filedialog
root = tk.Tk()
root.withdraw()
file_path = filedialog.askopenfilename()
上記コードにおいてのポイントはtkinter.filedialog.askopenfilename()の部分です。このコードでは、GUI操作(視覚的に行いやすい)を行います。具体的には、ファイル選択ダイアログボックスを開き、選択したファイルのパス.askopenfilenameを取得する関数です。
また、事前にfrom tkinter import filedialogにすることで
tkinter.filedialog.askopenfilename()をfiledialog.askopenfilename()と省略することができます。
ちなみに
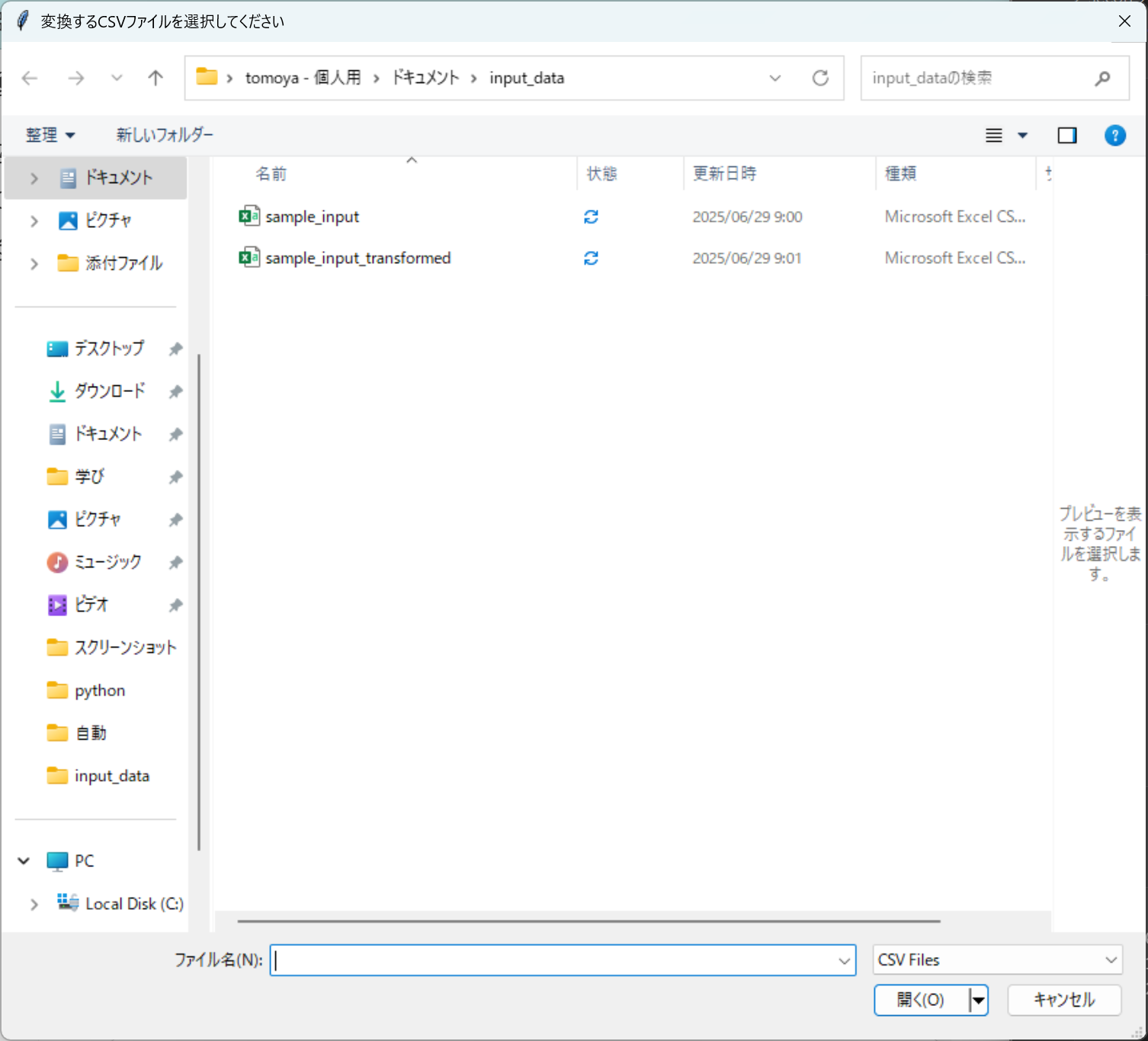
ちなみに、filedialog.askopenfilename()の()の中身はオプションで選択ダイアログボックスに文字列を表記することができます。
file_path = filedialog.askopenfilename(
title=“変換するCSVファイルを選択してください”,
filetypes=[(“CSV Files”, “*.csv”)]
)
こんな感じでダイアログボックスに表記されます。
csvファイルを読み込む
続いて上記で選択した、パスのファイルを読み込みます。
df = pd.read_csv(file_path, encoding=‘utf-8-sig’)
pandas.read_csv(path)でCSVファイルをPandasのDataFrameとして読み込みこむことができます。()の中身は、読み込みたいファイルのpathを指定します。また、データの文字化け防止したい場合はencoding='utf-8-sig'を記載することで対応できます。
データ整形作業
つづいて、データの整形作業を行います。ここでは、列挿入・行列の変換、列の結合処理を行っています。それぞれ解説していきます。
# melt処理とmain_dfの結合
main_df = df[[id_col, value_col]].copy()
main_df.insert(1, ‘プロダクト名’, value_col)
main_df.columns = [id_col, ‘プロダクト名’, ‘値’]
melted_df = df.melt(id_vars=[id_col], value_vars=melt_cols,
var_name=’プロダクト名’, value_name=’値’)
final_df = pd.concat([main_df, melted_df], ignore_index=True)





